前段时间写了MySql实时数据变更事件捕获kafka confluent之debezium,使用的是confluent整套的,接下来这篇将会介绍完整实战。
首先明确需求,公司订单数据越来越大,商户端和E端各种业务需求也越来越多查询越发复杂,我们想引进elasticsearch来实现查询和搜索。那么问题来了,实时更新的订单数据如何同步到es中,业务代码中insert或者update es中的index这肯定是不可取的,我们选择使用kafka和debezium结合使用,读取MySQLbinlog及时写入es.

本文将会实现一套完整的Debezium结合Kafka Connect实时捕获MySQL变更事件写入Elasticsearch并实现查询的流程.
安装
MySQL
MySQL的安装比较简单,同时需要MySQL开启binlog,为了简单我这里使用docker启动一个MySQL并且里面已创建有数据。
- docker安装 ```aidl docker run -it –rm –name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql:0.8
1 | |
1 | |
备注: http://localhost:8083/connectors/order-center-connector/config这个接口不但能更新connector还能创建,如果connector不存在的时候使它就会创建一个connector如果存在就去更新.
debezium提供了诸多配置参数,上图例子中只是提供了常用的配置,详细配置参考Debezium Connector for MySQL .
connector创建成功之后,可以通过http://localhost:8083/connectors/查看已经创建个的connector.

同时你还可以通过http://localhost:8083/connectors/order-center-connector/查看某一个connector的详细配置信息.

也可以通过http://localhost:8083/connectors/order-center-connector/status查看当前connector的详细状态,如果当前connector出现故障,也会在这里提示出来.

connector创建成功后,接下来应该测试debezium是否开始工作了,MySQL发生insert或者update 的时候有没有写入kafka.
[注意事项]
笔者在配置connector的过程中也遇到过了好多问题,一些比较重要的东西也记录下来了,如果你在使用过程中出现问题可以查看文末常见问题里面是否有同样的问题.
debezium kafka topic消费
在上面的debezium配置中可以看到参数database.server.name,database.whitelist,debezium connector会处理MySQL的binlog后对应数据库不同的表将消息发送到不通的topic上,其中这些topic的构成方式为:[database.server.name].[数据库名称].[表名称],记下来按步骤操作.
-
- 在kafka的安装目录下使用
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic trade_order_0.inventory.orders消费trade_order_0.inventory.orders这个topic.
- 在kafka的安装目录下使用
-
- 任意修改orders表的一行数据,然后回到第一步就可以观察到.

看到这样的结果说明debezium已经开始工作了.
spring boot消费kafka消息并且写入elasticsearch中
-
Demo代码已经在https://github.com/m65536/practice/tree/master/search/elasticsearch全部实现.下载后配合上面安装好了的环境可以直接启动运行(当前版本使用的6.5,如果需要使用2.X,es客户端配置略有不同).
-
使用创建index之前可以创建index template,使用简单并且方便灵活.
-
创建template
put http://localhost:9200/_template/{模板名称}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15{ "template": "trade-order-sales", "order": 0, "mappings": { "_default_": { "_source": { "enabled": true } }, "type": { "properties":{"orderNumber":{"type":"text"},"quantity":{"type":"text"},"productId":{"type":"text"},"purchaser":{"type":"date"},"orderDate":{"type":"text"},"purchaserName":{"type":"text"},"createDate":{"type":"date"}} } } }
-
启动项目测试
启动SpringBootElasticsearchApplication后,更改orders表任意数据,此时我们看到日志,再去观察es,如图.
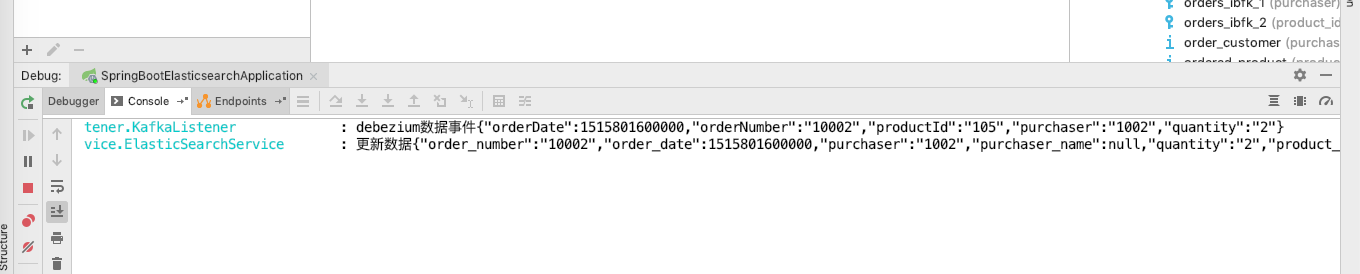
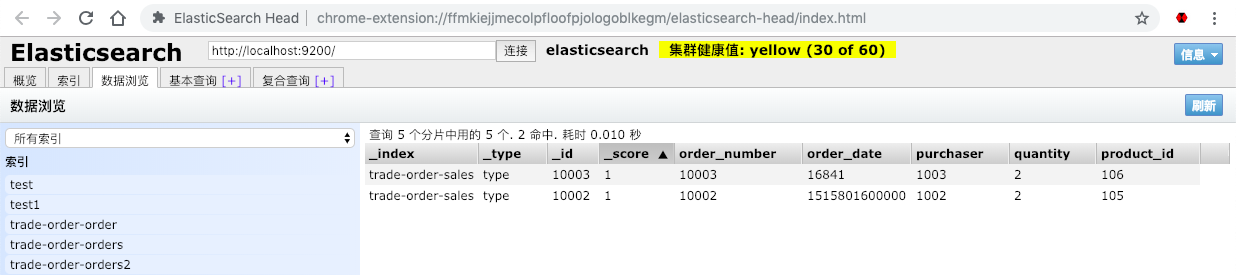
此时说明MySQL到connect到kafka再到server再到es整个流程通了,同时可以通过server去查询esTestController-http://localhost:8080/test/list

常见问题
- Unexpected exception while parsing statement alter table pay_cs_market_balance alter column balance_amt set default 0 at line 1
https://blog.csdn.net/lzufeng/article/details/81488524
- 如果配置无效
1 检查表白名单 2 检查database.server.id是否重复 3 检查其他配置重复是否
- 如何分词(version 2.X)
https://zhuanlan.zhihu.com/p/29183128 http://esuc.dev.rs.com:9200/_analyze?pretty&analyzer=keyword &text=SO5046240000014238
- 消费者乱码
保持写入消费使用的同一个序列化方式.
- 数据库
date,datetime,timestamp之类的字段,消费者收到少了8个小时或者多了8个小时这个问题主要是由于时区的问题,建议阅读官网文档Temporal values without time zone

解决办法
建议数据都改成timestamp(携带了时区)类型然后再kafka消费的时候使用Date对象接收,转成Date对象时区就是本地的了,再写入es就是你想要的了.